解释器(Interpreter)
解释器模式是一种行为型设计模式,核心思想是将特定语言的语法规则抽象为对象,通过这些对象构建 “抽象语法树”(Abstract Syntax Tree, AST),并定义解释器来执行语法树,从而实现对语言的解释执行。
它广泛应用于需要解析、解释自定义语法或表达式的场景,如公式计算、正则表达式、SQL 解析等。
解释器模式(Interpreter pattern): 使用解释器模式为语言创建解释器,通常由语言的语法和语法分析来定义。
定义
根据《设计模式:可复用面向对象软件的基础》(GoF)定义: 解释器模式(Interpreter Pattern)定义一个语言的语法表示,并定义一个解释器来解释该语言中的句子。
通俗来说:
- “语言”:指具有特定语法规则的符号集合(如算术表达式、布尔表达式);
- “语法表示”:用对象表示语法规则(如 “加法” 对应
AddExpression类,“数字” 对应NumberExpression类); - “解释器”:表达式对象自身实现 “解释” 方法,递归执行语法树以得到结果。
意图
为语言创建解释器,通常由语言的语法和语法分析来定义。
在软件开发中,经常会遇到需要解析和执行特定语法规则的场景,例如:
- 计算器需要解析 “1+2*3” 这类算术表达式并计算结果;
- 正则表达式引擎需要解析 “a [b-c]*d” 这类模式并匹配字符串;
- Android 的 Data Binding 需要解析 “@{user.name + '(' + user.age + ')'}” 这类表达式并绑定 UI;
- 自定义脚本语言(如游戏中的任务脚本)需要解释执行 “if (score> 100) then reward (50)”。
如果直接用硬编码(如大量if-else或switch)处理这些语法,会导致代码:
- 耦合度极高:语法规则与执行逻辑混杂,修改规则需重构大量代码;
- 扩展性差:新增语法(如给计算器加 “平方” 运算)需修改核心逻辑;
- 可读性低:复杂语法的解析逻辑会形成 “代码迷宫”。
为解决这些问题,解释器模式提出:将语法规则拆分为独立的 “表达式对象”,用对象组合构建语法树(对应完整表达式),再通过统一的 “解释” 方法执行语法树。这种方式让语法规则与执行逻辑解耦,新增规则只需新增表达式类,无需修改现有代码。
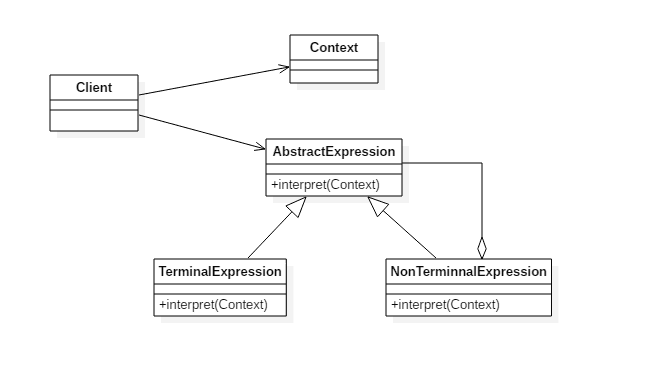
结构
解释器模式包含 5 个核心角色,各角色职责明确,共同构成语法解析与执行流程:
| 角色名称 | 核心职责 |
|---|---|
| 抽象表达式(AbstractExpression) | 定义所有表达式的统一接口,声明interpret(Context)方法(解释逻辑的入口)。 |
| 终结符表达式(TerminalExpression) | 对应语法中的 “终结符”(不可再拆分的基本单位,如算术表达式中的 “数字”、布尔表达式中的 “变量 a”),实现interpret方法处理自身逻辑。 |
| 非终结符表达式(NonterminalExpression) | 对应语法中的 “非终结符”(需拆分为子表达式,如算术表达式中的 “加法”“乘法”),内部包含子表达式(终结符 / 非终结符),interpret方法通过递归调用子表达式的interpret完成逻辑。 |
| 上下文(Context) | 存储解释过程中需要共享的数据(如变量值、中间结果),供所有表达式访问。 |
| 客户端(Client) | 1. 定义语法规则(构建抽象语法树 AST);2. 调用顶层表达式的interpret方法执行解释。 |
结构示意图:
Client → 构建AST → 顶层NonterminalExpression
↓
┌────────────────┼────────────────┐
↓ ↓ ↓
TerminalExpression NonterminalExpression TerminalExpression
↓
┌────────┴────────┐
↓ ↓
TerminalExpression TerminalExpression
类图
TerminalExpression: 终结符表达式,每个终结符都需要一个 TerminalExpression
Context: 上下文,包含解释器之外的一些全局信息
时序图
解释器模式的核心流程是 “构建语法树 → 递归解释”,以下是基于 “计算 1+2-3” 的时序图(用 Mermaid 描述):
sequenceDiagram
participant Client
participant Context
participant AddExpr (Nonterminal)
participant SubtractExpr (Nonterminal)
participant Num1 (Terminal)
participant Num2 (Terminal)
participant Num3 (Terminal)
%% 1. 客户端初始化上下文(可选,如无变量则可省略)
Client->>Context: 初始化(无变量,仅存储中间结果)
%% 2. 客户端创建终结符表达式(数字1、2、3)
Client->>Num1: new NumberExpression(1)
Client->>Num2: new NumberExpression(2)
Client->>Num3: new NumberExpression(3)
%% 3. 客户端构建语法树:先1+2,再减3
Client->>AddExpr: new AddExpression(Num1, Num2)
Client->>SubtractExpr: new SubtractExpression(AddExpr, Num3)
%% 4. 客户端触发顶层表达式解释
Client->>SubtractExpr: interpret(Context)
%% 5. 非终结符递归调用子表达式解释
SubtractExpr->>AddExpr: interpret(Context)
AddExpr->>Num1: interpret(Context)
Num1-->>AddExpr: 返回1
AddExpr->>Num2: interpret(Context)
Num2-->>AddExpr: 返回2
AddExpr-->>SubtractExpr: 返回1+2=3
SubtractExpr->>Num3: interpret(Context)
Num3-->>SubtractExpr: 返回3
%% 6. 解释完成,返回结果给客户端
SubtractExpr-->>Client: 返回3-3=0
时序核心:非终结符表达式(如SubtractExpr)通过递归调用子表达式的interpret方法,逐层拆解语法规则,最终汇总结果。
模式分析
解释器模式的核心是 “语法即对象”,通过以下机制实现语法解析与执行:
1. 语法树的构建与解释
- 构建过程:客户端根据语法规则,将终结符和非终结符组合成树形结构(抽象语法树 AST),顶层节点为完整表达式;
- 解释过程:从顶层非终结符开始,递归调用子表达式的
interpret方法,逐层拆解语法,最终汇总结果(类似 “后序遍历”)。
2. 职责分离
- 抽象表达式定义接口,终结符 / 非终结符专注于自身语法的解释逻辑;
- 上下文集中管理共享数据,避免表达式间直接耦合;
- 客户端仅负责构建语法树,不参与解释逻辑,符合 “单一职责原则”。
3. 可扩展性体现
若需给计算器新增 “乘法*” 运算,只需新增MultiplyExpression类(继承Expression),无需修改现有AddExpression、SubtractExpression:
public class MultiplyExpression extends Expression {
private Expression leftExpr;
private Expression rightExpr;
public MultiplyExpression(Expression leftExpr, Expression rightExpr) {
this.leftExpr = leftExpr;
this.rightExpr = rightExpr;
}
@Override
public int interpret(Context context) {
return leftExpr.interpret(context) * rightExpr.interpret(context);
}
}
客户端可直接使用:new MultiplyExpression(addExpr, num3)(计算(1+2)*3),符合 “开闭原则”。
实现1
以 “简单算术表达式解释器” 为例(支持整数的加法+和减法-),用 Java 实现解释器模式的核心角色。
1. 步骤 1:定义抽象表达式(AbstractExpression)
统一所有表达式的接口,声明interpret方法:
/**
* 抽象表达式:定义解释器的统一接口
*/
public abstract class Expression {
/**
* 解释方法:根据上下文计算表达式结果
* @param context 上下文(存储中间结果或变量)
* @return 表达式解释结果(此处为int类型)
*/
public abstract int interpret(Context context);
}
2. 步骤 2:定义上下文(Context)
存储解释过程中的共享数据(此处简化为 “无变量,仅传递计算环境”,复杂场景可存储变量值):
/**
* 上下文:存储解释过程中的共享信息
* 此处简化实现,若支持变量(如"a+b"),可添加Map<String, Integer>存储变量值
*/
public class Context {
// 若有变量,可添加:private Map<String, Integer> variableMap = new HashMap<>();
// 提供setVariable、getVariable方法操作变量
}
3. 步骤 3:定义终结符表达式(TerminalExpression)
对应算术表达式中的 “数字”(不可再拆分的基本单位):
/**
* 终结符表达式:处理数字(语法中的终结符)
*/
public class NumberExpression extends Expression {
private int number; // 存储数字值
public NumberExpression(int number) {
this.number = number;
}
// 解释逻辑:直接返回自身存储的数字(无需依赖上下文)
@Override
public int interpret(Context context) {
return this.number;
}
}
4. 步骤 4:定义非终结符表达式(NonterminalExpression)
对应算术表达式中的 “加法” 和 “减法”(需拆分为两个子表达式):
(1)加法表达式(AddExpression)
/**
* 非终结符表达式:处理加法(语法中的非终结符:a + b)
*/
public class AddExpression extends Expression {
private Expression leftExpr; // 左子表达式(如a)
private Expression rightExpr; // 右子表达式(如b)
// 构造时传入两个子表达式
public AddExpression(Expression leftExpr, Expression rightExpr) {
this.leftExpr = leftExpr;
this.rightExpr = rightExpr;
}
// 解释逻辑:递归解释左、右子表达式,再相加
@Override
public int interpret(Context context) {
// 左子表达式结果 + 右子表达式结果
return leftExpr.interpret(context) + rightExpr.interpret(context);
}
}
(2)减法表达式(SubtractExpression)
/**
* 非终结符表达式:处理减法(语法中的非终结符:a - b)
*/
public class SubtractExpression extends Expression {
private Expression leftExpr; // 左子表达式(如a)
private Expression rightExpr; // 右子表达式(如b)
public SubtractExpression(Expression leftExpr, Expression rightExpr) {
this.leftExpr = leftExpr;
this.rightExpr = rightExpr;
}
// 解释逻辑:递归解释左、右子表达式,再相减
@Override
public int interpret(Context context) {
return leftExpr.interpret(context) - rightExpr.interpret(context);
}
}
5. 步骤 5:客户端(Client)构建语法树并执行解释
客户端负责定义语法规则(构建抽象语法树 AST),并触发顶层表达式的解释:
/**
* 客户端:构建抽象语法树,执行解释
*/
public class Client {
public static void main(String[] args) {
// 1. 初始化上下文(此处无变量,仅创建实例)
Context context = new Context();
// 2. 构建语法树:计算 1 + 2 - 3
// 终结符:1、2、3
Expression num1 = new NumberExpression(1);
Expression num2 = new NumberExpression(2);
Expression num3 = new NumberExpression(3);
// 非终结符:1+2(左子树)
Expression addExpr = new AddExpression(num1, num2);
// 顶层非终结符:(1+2) - 3(完整语法树)
Expression subtractExpr = new SubtractExpression(addExpr, num3);
// 3. 执行解释,获取结果
int result = subtractExpr.interpret(context);
System.out.println("1 + 2 - 3 = " + result); // 输出:1 + 2 - 3 = 0
}
}
代码执行流程
客户端创建
Context,无变量需设置;创建终结符
num1(1)、num2(2)、num3(3);构建语法树:
addExpr(num1, num2)→subtractExpr(addExpr, num3);调用
subtractExpr.interpret(context)subtractExpr先调用addExpr.interpret(context);addExpr调用num1.interpret()(返回 1)和num2.interpret()(返回 2),相加得 3;subtractExpr再调用num3.interpret()(返回 3),相减得 0;
返回结果 0,客户端打印。
实现2
以下是一个规则检验器实现,具有 and 和 or 规则,通过规则可以构建一颗解析树,用来检验一个文本是否满足解析树定义的规则。
例如一颗解析树为 D And (A Or (B C)),文本 "D A" 满足该解析树定义的规则。
这里的 Context 指的是 String。
public abstract class Expression {
public abstract boolean interpret(String str);
}
public class TerminalExpression extends Expression {
private String literal = null;
public TerminalExpression(String str) {
literal = str;
}
public boolean interpret(String str) {
StringTokenizer st = new StringTokenizer(str);
while (st.hasMoreTokens()) {
String test = st.nextToken();
if (test.equals(literal)) {
return true;
}
}
return false;
}
}
public class AndExpression extends Expression {
private Expression expression1 = null;
private Expression expression2 = null;
public AndExpression(Expression expression1, Expression expression2) {
this.expression1 = expression1;
this.expression2 = expression2;
}
public boolean interpret(String str) {
return expression1.interpret(str) && expression2.interpret(str);
}
}
public class OrExpression extends Expression {
private Expression expression1 = null;
private Expression expression2 = null;
public OrExpression(Expression expression1, Expression expression2) {
this.expression1 = expression1;
this.expression2 = expression2;
}
public boolean interpret(String str) {
return expression1.interpret(str) || expression2.interpret(str);
}
}
public class Client {
/**
* 构建解析树
*/
public static Expression buildInterpreterTree() {
// Literal
Expression terminal1 = new TerminalExpression("A");
Expression terminal2 = new TerminalExpression("B");
Expression terminal3 = new TerminalExpression("C");
Expression terminal4 = new TerminalExpression("D");
// B C
Expression alternation1 = new OrExpression(terminal2, terminal3);
// A Or (B C)
Expression alternation2 = new OrExpression(terminal1, alternation1);
// D And (A Or (B C))
return new AndExpression(terminal4, alternation2);
}
public static void main(String[] args) {
Expression define = buildInterpreterTree();
String context1 = "D A";
String context2 = "A B";
System.out.println(define.interpret(context1));
System.out.println(define.interpret(context2));
}
}
true
false
实例:布尔表达式解释器
再举一个 “布尔表达式解释器” 实例(支持变量a/b/c、逻辑与AND、逻辑或OR),进一步展示解释器模式的灵活性。
1. 抽象表达式
public abstract class BooleanExpression {
public abstract boolean interpret(Context context);
}
2. 上下文(存储变量值)
public class Context {
// 存储变量名→布尔值的映射(如"a"→true)
private Map<String, Boolean> variableMap = new HashMap<>();
public void setVariable(String varName, boolean value) {
variableMap.put(varName, value);
}
public boolean getVariable(String varName) {
return variableMap.getOrDefault(varName, false);
}
}
3. 终结符表达式(变量)
public class VariableExpression extends BooleanExpression {
private String varName; // 变量名(如"a")
public VariableExpression(String varName) {
this.varName = varName;
}
// 从上下文获取变量值
@Override
public boolean interpret(Context context) {
return context.getVariable(varName);
}
}
4. 非终结符表达式(AND/OR)
// 逻辑与表达式
public class AndExpression extends BooleanExpression {
private BooleanExpression leftExpr;
private BooleanExpression rightExpr;
public AndExpression(BooleanExpression leftExpr, BooleanExpression rightExpr) {
this.leftExpr = leftExpr;
this.rightExpr = rightExpr;
}
@Override
public boolean interpret(Context context) {
return leftExpr.interpret(context) && rightExpr.interpret(context);
}
}
// 逻辑或表达式
public class OrExpression extends BooleanExpression {
private BooleanExpression leftExpr;
private BooleanExpression rightExpr;
public OrExpression(BooleanExpression leftExpr, BooleanExpression rightExpr) {
this.leftExpr = leftExpr;
this.rightExpr = rightExpr;
}
@Override
public boolean interpret(Context context) {
return leftExpr.interpret(context) || rightExpr.interpret(context);
}
}
5. 客户端(解释 “a AND (b OR c)”)
public class Client {
public static void main(String[] args) {
// 1. 初始化上下文,设置变量值:a=true, b=false, c=true
Context context = new Context();
context.setVariable("a", true);
context.setVariable("b", false);
context.setVariable("c", true);
// 2. 构建语法树:a AND (b OR c)
BooleanExpression a = new VariableExpression("a");
BooleanExpression b = new VariableExpression("b");
BooleanExpression c = new VariableExpression("c");
BooleanExpression bOrC = new OrExpression(b, c); // b OR c
BooleanExpression aAndBOrC = new AndExpression(a, bOrC); // a AND (b OR c)
// 3. 执行解释
boolean result = aAndBOrC.interpret(context);
System.out.println("a AND (b OR c) = " + result); // 输出:true AND (false OR true) = true
}
}
优点
- 极强的可扩展性 新增语法规则只需新增对应的表达式类(如新增 “乘法” 只需加
MultiplyExpression),无需修改现有代码,完全符合 “开闭原则”。 - 语法规则清晰可控 每个语法规则对应一个独立的表达式类,职责单一,代码可读性高,便于维护和调试(如 “加法” 逻辑仅在
AddExpression中)。 - 易于实现简单语法 对于简单语法(如算术表达式、布尔表达式),无需依赖复杂的解析工具(如 ANTLR),手动实现成本低。
- 可复用性强 表达式类可在不同语法树中复用(如
NumberExpression(5)可同时用于 “5+3” 和 “10-5”)。
缺点
- 复杂语法导致 “类爆炸” 若语法规则复杂(如支持括号优先级、函数调用、循环语句),需为每个细分规则创建表达式类(如
ParenthesisExpression、FunctionExpression),导致类数量急剧增加,维护成本飙升。 - 解释效率低 解释过程依赖递归调用(逐层拆解语法树),且可能存在重复计算(如表达式 “a+b+a” 中
a被解释两次),在复杂语法场景下性能较差。 - 难以处理复杂语法 对于工业级复杂语法(如 Java 代码编译、SQL 解析),解释器模式的递归结构和类爆炸问题会使其无法胜任,此时更适合使用专业解析工具(如 ANTLR、JavaCC)。
适用环境
解释器模式仅适用于语法规则简单、需频繁扩展且解释效率要求不高的场景,具体包括:
- 需解释执行自定义 “小型语言” 或 “表达式” 的场景:
- 配置文件中的条件表达式(如 “if (temperature> 30) then openFan”);
- UI 框架中的数据绑定表达式(如 Android Data Binding、Vue 的
{{}}); - 游戏中的简单脚本(如 “玩家触发 A 事件则执行 B 动作”)。
- 语法规则频繁变化但结构简单的场景:
- 计算器新增运算(如开平方、取模);
- 布尔表达式新增逻辑(如 “异或 XOR”)。
- 不适用场景:
- 语法规则复杂(如编程语言编译、SQL 完整解析);
- 解释效率要求高(如高频次表达式计算)。
模式应用
解释器模式在实际开发中应用广泛,以下是典型场景:
- 正则表达式引擎 正则表达式(如 “^[a-zA-Z0-9]+$”)的解析和匹配基于解释器模式:
- 终结符:单个字符(如
a、9)、元字符(如^、$); - 非终结符:量词(如
+、*)、逻辑组合(如[a-z]); - 解释过程:引擎构建语法树,递归匹配输入字符串。
- 终结符:单个字符(如
- EL 表达式解析 JSP 的 EL 表达式(如
${user.age > 18 ? '成年' : '未成年'})、Android Data Binding 表达式(如@{viewModel.totalPrice + '元'})均采用解释器模式解析表达式并绑定数据。 - SQL 解析器 数据库的 SQL 解析过程(如解析
SELECT name FROM user WHERE age > 20):- 语法树节点对应 SQL 的各部分(
SelectClause、FromClause、WhereClause); - 解释器将语法树转换为执行计划,最终查询数据。
- 语法树节点对应 SQL 的各部分(
- 自定义脚本解释器 游戏或工具软件中的自定义脚本(如 Unity 的 C# 脚本简化版、自动化测试工具的脚本),通过解释器模式解析脚本语法并执行逻辑。
模式扩展
解释器模式可与其他设计模式结合,解决其固有缺陷或扩展功能:
- 结合组合模式(Composite Pattern) 解释器模式的抽象语法树本质是 “组合结构”:
- 非终结符表达式 = 组合节点(Composite),包含子表达式;
- 终结符表达式 = 叶子节点(Leaf),无子类; 两者结合可更清晰地管理语法树的层级结构,复用组合模式的遍历、添加、删除节点功能。
- 结合享元模式(Flyweight Pattern) 解决 “重复终结符导致的对象冗余” 问题:
- 场景:表达式 “5+5+5” 中,
NumberExpression(5)被创建 3 次; - 优化:用享元模式创建 “对象池”,缓存
NumberExpression(5)实例,重复使用,减少对象创建。
- 场景:表达式 “5+5+5” 中,
- 结合备忘录模式(Memento Pattern) 保存上下文(Context)的状态,支持解释过程的回滚:
- 场景:表达式解释过程中需要回溯(如语法错误时恢复到上一步状态);
- 实现:备忘录模式保存
Context的历史状态,需回滚时从备忘录恢复。
- 结合访问者模式(Visitor Pattern) 为语法树添加新操作(如语法校验、代码生成),无需修改表达式类:
- 场景:需为算术表达式添加 “语法校验”(如检测除数为 0)或 “表达式转字符串” 功能;
- 实现:访问者模式定义
Visitor接口,表达式类提供accept(Visitor)方法,新增操作只需新增Visitor实现类。
Android中的应用
在 Android 开发中,解释器模式虽然不像观察者模式、工厂模式那样被频繁直接使用,但在许多框架和系统组件的底层实现中,都能看到其核心思想(将语法规则抽象为对象并解释执行)的应用。以下是 Android 中典型的解释器模式应用场景:
1. 布局文件解析(XML 布局解析)
Android 的 XML 布局文件(如activity_main.xml)本质上是一种自定义标记语言,系统需要解析其中的标签(如<TextView>、<LinearLayout>)和属性(如layout_width、text),并将其转换为内存中的 View 对象。这一过程大量运用了解释器模式的思想:
- 抽象表达式:系统内部定义了一套解析 XML 标签和属性的接口(如
XmlPullParser相关处理逻辑)。 - 终结符表达式:对应 XML 中的基本元素(如
android:id、android:text等属性的解析器)。 - 非终结符表达式:对应容器标签(如
<LinearLayout>、<ConstraintLayout>)的解析器,需要递归解析其子标签(子 View)。 - 上下文(Context):解析过程中传递的
AttributeSet(存储属性键值对)、Resources(资源管理)等。 - 解释过程:
LayoutInflater通过解析 XML 构建 View 树,本质是对 XML 语法树的递归解释执行。
2. 数据绑定(Data Binding)表达式解析
Android Data Binding 库允许在 XML 中使用表达式(如@{user.name}、@{total + 10})实现 UI 与数据的自动绑定,其表达式解析器是解释器模式的典型应用:
- 语法规则:支持算术运算(
+、-)、逻辑判断(&&、||)、空安全(?.)、三元运算符(?:)等。 - 抽象表达式:Data Binding 内部定义了表达式的抽象接口(如
Expression类)。 - 终结符表达式:对应变量(
user)、常量(10)的解析器。 - 非终结符表达式:对应运算符(如
+的AddExpression、&&的AndExpression),需要递归解析左右子表达式。 - 解释过程:当数据变化时,Data Binding 解释器会重新计算表达式结果,并更新 UI(如
TextView的text属性)。
示例: XML 中的android:text="@{user.age > 18 ? 成年:未成年}"会被解析为一个条件表达式语法树,解释器根据user.age的值动态返回结果。
3. 资源引用解析(如@string/app_name)
Android 中资源引用(如@string/、@drawable/、@dimen/)的解析过程也运用了解释器模式:
- 语法规则:资源引用有固定格式(
@[package:]type/name,如@android:color/white)。 - 终结符表达式:解析资源类型(
string、color)、资源名称(app_name)的组件。 - 非终结符表达式:解析完整资源路径的组件,处理包名(如默认包、
android系统包)、类型、名称的组合逻辑。 - 上下文:
Resources对象(管理资源索引、配置信息)。 - 解释过程:系统通过解析资源引用字符串,最终找到对应的内存资源(如字符串、图片)。
4. AndroidManifest.xml 解析
AndroidManifest.xml包含应用的核心配置(组件声明、权限、intent-filter 等),其解析过程需要处理复杂的语法规则:
- 语法规则:如
<activity>标签、<intent-filter>的<action>/<category>子标签、android:name等属性。 - 非终结符表达式:
<application>标签解析器需要递归解析其内部的<activity>、<service>等子标签;<intent-filter>解析器需要组合<action>和<category>的逻辑。 - 解释结果:解析后生成应用的组件信息、权限列表等,供系统启动和管理应用使用。
5. SQLite 查询解析(SQL 语句解释)
Android 通过 SQLite 数据库存储数据时,SQL 语句(如SELECT * FROM user WHERE age > 18)的解析依赖解释器模式:
- 语法规则:SQL 语言有严格的语法规范(SELECT 子句、FROM 子句、WHERE 条件等)。
- 抽象表达式:SQLite 内部的语法解析接口。
- 非终结符表达式:WHERE 条件中的逻辑表达式(如
age > 18 AND name LIKE 'A%')解析器,需要递归处理比较运算符、逻辑运算符。 - 解释过程:SQLite 引擎将 SQL 语句解析为语法树,再转换为执行计划,最终操作数据表。
6. 属性动画表达式解析(ValueAnimator 的 Evaluator)
属性动画中,ValueAnimator支持通过表达式定义动画插值逻辑(如自定义TypeEvaluator),本质是对 “动画进度→属性值” 映射规则的解释:
- 语法规则:如 “从 0 到 100 的线性变化”“先加速后减速的曲线变化”。
- 终结符表达式:动画的起始值、结束值解析。
- 非终结符表达式:插值算法(如
AccelerateDecelerateInterpolator)解析器,根据时间进度(0~1)计算当前值。 - 解释过程:动画每帧刷新时,解释器根据当前进度计算属性值,驱动 UI 更新。
除了之前提到的场景,解释器模式在 Android 中还有一些更具体或偏底层的应用场景,这些场景通常涉及对特定语法、规则或表达式的解析与执行,以下是几个典型例子:
7. ConstraintLayout 约束表达式解析
ConstraintLayout 作为 Android 主流布局,其核心功能是通过 “约束规则” 定义控件间的位置关系(如app:layout_constraintStart_toEndOf、app:layout_constraintDimensionRatio)。这些约束本质上是一种自定义语法,其解析过程依赖解释器模式:
- 语法规则:约束表达式包含 “源控件”“目标控件”“关系类型”(如
toStartOf、toEndOf)、“偏移量”(如margin)等要素,例如app:layout_constraintTop_toBottomOf="@id/title"。 - 终结符表达式:解析单个控件 ID(如
@id/title)、偏移量数值(如16dp)的组件。 - 非终结符表达式:解析完整约束关系的组件(如
Top_toBottomOf规则),需要组合源控件、目标控件和偏移量的信息,并递归处理嵌套约束(如链式约束app:layout_constraintHorizontal_chainStyle)。 - 解释过程:ConstraintLayout 在测量布局时,会解释所有约束表达式,计算每个控件的最终位置和大小,这一过程需要递归处理依赖关系(如 A 依赖 B,B 依赖 C)。
8. Android 权限表达式解析(如uses-permission的maxSdkVersion)
AndroidManifest 中声明权限时,支持通过maxSdkVersion等属性限制权限的适用范围(如<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE" android:maxSdkVersion="28"/>)。系统对这类权限规则的解析也运用了解释器模式:
- 语法规则:权限声明包含权限名称、
maxSdkVersion、minSdkVersion等条件,这些条件共同决定 “在哪些系统版本中启用该权限”。 - 终结符表达式:解析权限名称(如
READ_EXTERNAL_STORAGE)、版本号(如28)的组件。 - 非终结符表达式:解析 “版本范围判断” 的逻辑(如 “当前 SDK 版本 ≤ maxSdkVersion”),组合多个条件确定权限是否生效。
- 解释过程:系统安装或运行应用时,解释权限表达式,判断当前环境(SDK 版本)是否满足权限启用条件,决定是否授予权限。
9. 自定义 View 的属性解析(TypedArray 与 declare-styleable)
当我们通过declare-styleable为自定义 View 定义属性(如<attr name="customColor" format="color"/>)时,系统对这些属性的解析过程本质是对 “属性语法” 的解释:
- 语法规则:属性定义包含名称(
customColor)、格式(color、dimension、boolean等)、默认值等,XML 中使用app:customColor="@color/red"引用。 - 终结符表达式:解析属性格式(如
color类型对应getColor()方法)、默认值的组件。 - 非终结符表达式:解析 “属性引用” 的组件(如
@color/red需要先解析为资源 ID,再通过资源系统获取颜色值),处理格式转换(如将字符串"16dp"转换为像素值)。 - 解释过程:自定义 View 在
obtainStyledAttributes时,系统通过解释属性表达式,从TypedArray中提取并转换属性值,供 View 使用。
10. WorkManager 的约束条件解析
WorkManager 用于调度后台任务,支持通过Constraints定义任务执行的条件(如网络类型、充电状态、存储容量等),例如:
Constraints constraints = new Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED) // 网络连接时
.setRequiresCharging(true) // 充电时
.build();
这些约束条件的解析和判断依赖解释器模式:
- 语法规则:约束条件包含 “网络类型”“充电状态”“电池电量” 等原子条件,以及条件间的逻辑关系(如 “且” 关系:所有条件必须同时满足)。
- 终结符表达式:解析单个原子条件(如
NetworkType.CONNECTED)的判断逻辑(检查当前网络状态)。 - 非终结符表达式:解析条件组合关系(如 “所有约束必须满足” 的
AndExpression),递归判断每个原子条件,最终确定是否满足执行条件。 - 解释过程:WorkManager 调度任务时,解释约束表达式,若所有条件满足则执行任务,否则等待条件触发。
11. Dex 文件解析(字节码指令解释)
Android 应用的代码最终编译为 Dex 文件(包含 Dalvik/ART 虚拟机字节码),虚拟机执行 Dex 文件时,需要解析字节码指令(如invoke-virtual、add-int),这是解释器模式的底层应用:
- 语法规则:Dex 字节码有严格的指令集规范(操作码、操作数),例如
add-int v0, v1, v2表示 “v1 + v2 的结果存入 v0”。 - 终结符表达式:解析操作数(如寄存器
v0、常量值)的组件。 - 非终结符表达式:解析指令逻辑(如
add-int对应加法运算,invoke-virtual对应方法调用),需要组合操作数和上下文(如当前栈帧、对象实例)。 - 解释过程:ART 虚拟机的解释器模式执行引擎(区别于 JIT/AOT 编译)会逐条解释字节码指令,转换为机器码执行,这是最底层的 “语法解释”。
12. 总结
Android 中解释器模式的应用,核心是对 “自定义语法规则” 的解析与执行,例如 XML 标签、数据绑定表达式、资源引用等。这些场景的共性是:
- 存在明确的语法规则(如 XML 标签格式、表达式运算符);
- 需要将语法转换为具体行为(如创建 View、计算属性值);
- 语法可能扩展(如 Data Binding 新增运算符),需通过新增 “表达式类” 实现扩展。
这些场景的共性是:存在需要解析的 “规则 / 语法”,且规则可拆分为原子单元和组合逻辑。解释器模式通过将规则抽象为表达式对象,实现了语法解析的灵活性和可扩展性 —— 例如,当 ConstraintLayout 新增一种约束类型(如layout_constraintCircle)时,只需新增对应的表达式解析逻辑,无需修改整体框架。
理解这些应用,有助于我们在开发自定义框架(如自定义配置解析器、业务规则引擎)时,更合理地运用解释器模式处理复杂语法场景。也有助于我们在自定义场景(如实现自定义配置解析、业务规则引擎)中合理运用解释器模式,提升代码的可扩展性。
总结
解释器模式的核心是 “将语法规则对象化”,通过抽象语法树(AST)和递归解释,实现对特定语言的解析与执行。它的价值体现在 “简单语法的灵活扩展”,但在复杂语法场景下会暴露 “类爆炸” 和 “效率低” 的缺陷。
- 核心思想:语法即对象,递归解释;
- 适用场景:简单语法、需频繁扩展、解释效率要求低;
- 使用权衡:优先用于小型表达式或自定义语法,复杂场景选择专业解析工具(如 ANTLR);
- 设计原则:符合开闭原则(扩展语法易)、单一职责原则(表达式类专注解释)。
理解解释器模式,不仅能解决 “自定义语法解析” 问题,更能培养 “将复杂规则拆解为对象” 的设计思维,为应对灵活多变的业务需求提供思路。
复杂解析器工具
JavaCC
JavaCC是一种用于生成解析器的编译器编写工具。它的主要优势在于它的灵活性和可扩展性。JavaCC允许开发人员根据自己的需求定制解析器,并且可以轻松地将其集成到现有的应用程序中。
JavaCC的优势包括:
灵活性:JavaCC允许开发人员根据自己的需求定制解析器,并且可以轻松地将其集成到现有的应用程序中。 可扩展性:JavaCC支持多种语言,包括Java、C++、C#和Python等,并且可以轻松地扩展到其他语言。 高效性:JavaCC使用了高效的算法和数据结构,可以快速地生成解析器,并且可以处理大量的输入数据。 可靠性:JavaCC提供了严格的语法检查和错误处理机制,可以确保解析器的正确性和可靠性。
ANTLR
ANTLR(ANother Tool for Language Recognition)
是另一种用于生成解析器的编译器编写工具,它也具有类似的优势。ANTLR支持多种目标语言,包括Java、C++、C#、Python、JavaScript等,并且可以轻松地扩展到其他语言。ANTLR提供了严格的语法检查和错误处理机制,可以确保解析器的正确性和可靠性。
总之,JavaCC和ANTLR都是非常有用的工具,可以帮助开发人员快速地生成解析器,并且可以根据自己的需求定制解析器。